Deep Reinforcement Learning Controller for Autonomous Tracking of Evasive Ground Target
During the fall semester of 2021, I spent a large chunk of my time tackling the problem of using deep reinforcement learning (RL) for target tracking of an evasive agent with and without the presence of occlusions. This problem is challenging for a few reasons:
- A 6-Degree-of-Freedom (DOF) system is considered, with dynamics modelled after a real hexarotor.
- The visual sensor used by the agent is non-gimballed, meaning the agent must directly control its body dynamics to change camera frame.
- The agent does not have information about the location or the existence of occlusions.
- The agent does not have access to maps, terrain features, or landmarks.
Abstract
Tracking the motion of an evasive, or even hostile, maneuvering ground target based on no percepts other than aerial images is a challenge that is relevant to military and commercial applications. This paper investigates the problem of tracking such a target using a multirotor unmanned air system with a non-gimballed optical sensor. The fixed sensor makes the problem challenging because the vehicle must use its dynamics and therefore attitude to change the sensor’s field of view. A Soft Actor-Critic reinforcement learning controller is developed to address the maneuvering ground target tracking problem for various target movement types including a sinusoidal motion, random motion, and evasive motion. The addition of ground occlusions which block the agent’s view of the target is also investigated. This is challenging because the reinforcement learning agent does not have information about the location or the existence of occlusions, but must still generate actions which track the target. Results in a simulated environment demonstrate the effectiveness of the learned policy. Consistent indefinite tracking is achieved with the mean distance of the target from the center of the image varying from 23 to 27 pixels for all motion types tested. Selection of the command rate, the rate at which the agent can generate actions, is also investigated. Faster command rates from the learned policy are shown to be less effective for tracking a maneuvering ground target since the agent needs to perform a greater number of correct sequential actions. Finally, the agent is able to successfully track a randomly moving target with the presence of occlusions.
Below, I will summarize the problem, theory and key results of this paper. For details please read the full paper here.
Reinforcement Learning
A learning based approach was used to tackle the target tracking problem for a few reasons:
- In a learning based approach, the bulk of the computation can be done offline, making the deployed controller lightweight and efficient when deployed online.
- Terrain features, maps, or landmarks are not required for successful tracking as is the case in some of the literature for traditional control applications.
- Only the target location in the image frame is required.
With that established, I will give a very brief overview of the type of learning method used in this work: reinforcment learning. In reinforcement learning, the goal is to train an agent to learn the parameters \(\theta\) of a policy (or controller) \(\pi_{\theta}\) which maps the observation vector \(\boldsymbol{o}\) of a partially-observable environment to the action vector \(\boldsymbol{a}\) of the agent. In a fully-observable environment, this mapping is done from the state vector \(\boldsymbol{s}\) to actions \(\boldsymbol{a}\). The agent is evaluated using the scalar reward signal r, which, along with the states, is outputted by the environment. This is illustrated in the following figure.
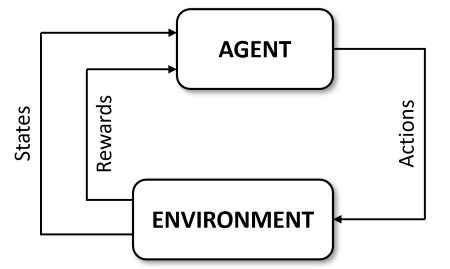
For the research herein, the environment is assumed to be fully observable.
Problem Formulation
The target tracking problem and the approach taken can be formalized as a reinforcement learning problem. The specific RL algorithm used is Soft Actor-Critic (SAC) from Stable Baselines3 [1]. SAC is an off-policy actor-critic algorithm that is designed to maximize expected reward while also maximizing entropy [2]. The environment is represented by the UAS, camera, ground target, and occlusions in certain cases. The state-space contains the aircraft states and target pixel position in the camera frame, \(X_T\) and \(Y_T\). The aircraft states are internal North-East-Down (NED) position (x, y, z), Forward-Right-Down (FRD) body frame translational velocities (u, v, w), FRD body frame rotational rates (p, q, r), and a 3-2-1 Euler angle rotation sequence from the NED frame to the FRD frame (yaw \(\psi\), pitch \(\theta\), and roll \(\phi\)). The agent makes high-level commands, with actions in the set given below, where \(z_{cmd}\) is the commanded inertial down position (negative altitude), \(u_{cmd}\) is the commanded body frame forward velocity, \(v_{cmd}\) is the commanded body frame lateral velocity, and \(r_{cmd}\) is commanded rotational rate about the body frame down axis (yaw rate when the vehicle is level).
\[\begin{equation} \mathcal{S} = \{X_T,Y_T,x,y,z,u,v,w,p,q,r,\phi,\theta,\psi\} \end{equation}\] \[\begin{equation} \mathcal{A} = \{z_{cmd},u_{cmd},v_{cmd},r_{cmd}\} \end{equation}\]Let \(X_{T,MAX}\) and \(Y_{T,MAX}\) be the maximum pixel locations before the target exits the image in the x and y directions, respectively. The camera coordinate frame is centered on the image, so \(X_{T,MAX}\) and \(Y_{T,MAX}\) are equivalent to one-half the resolution of the camera. The actions made by the agent are evaluated using the reward function given below. The reward function incentivizes the agent to keep the target close to the center of the camera frame. The agent will receive a very large negative reward if the target leaves the camera frame or if the target is obstructed from view by the occlusions. Let \(\bar{X}_T\) be \(X_T\) normalized by \(X_{T,MAX}\) and \(\bar{Y}_T\) be \(Y_T\) normalized by \(Y_{T,MAX}\) where:
\[\begin{equation} r = \begin{cases} 40 & ~ \bar{X}_T < 0.15 \text{ and } \bar{Y}_T < 0.15 \text{ and not obstructed}\\ 20*\left(1 -\frac{\sqrt[]{X_T^2 + Y_T^2}} {\sqrt[]{X_{T,MAX}^2 + Y_{T,MAX}^2 }} \right) & \text{ Not prior case and } \bar{X}_T < 0.80 \text{ and } \bar{Y}_T < 0.80 \text{ and not obstructed}\\ -40 & \text{ Not prior cases and } \bar{X}_T < 1.00 \text{ and } \bar{Y}_T < 1.00 \text{ and not obstructed} \\ -80 & \text{ Otherwise} \end{cases} \end{equation}\]The RL agent takes actions in the simulated environment and receives rewards based on those actions. Over time, the RL agent converges on a policy that will produce consistently high rewards. The agent learns the behavior that will maximize reward over the course of many environment interactions (i.e. time steps). These environment interactions are divided into episodes. A new episode begins when the environment is reset. During a reset, the UAS RL agent is spawned at the origin and at a predefined initial altitude with no rotation, no translational velocity, and no angular velocity. The target is spawned in a random location within the agent’s camera frame. The agent will take actions and receive rewards until episode end criteria are reached. For the case of no occlusions, the end criteria are reached if the target goes out of the image frame, or if the episode time exceeds a threshold value. Episodes with occlusions will also end if the episode time exceeds the same threshold value. However, for the case of occlusions, a maximum out-of-frame time of 90 seconds is set, to allow the episode to continue while the target is not in the image frame (i.e. occluded).
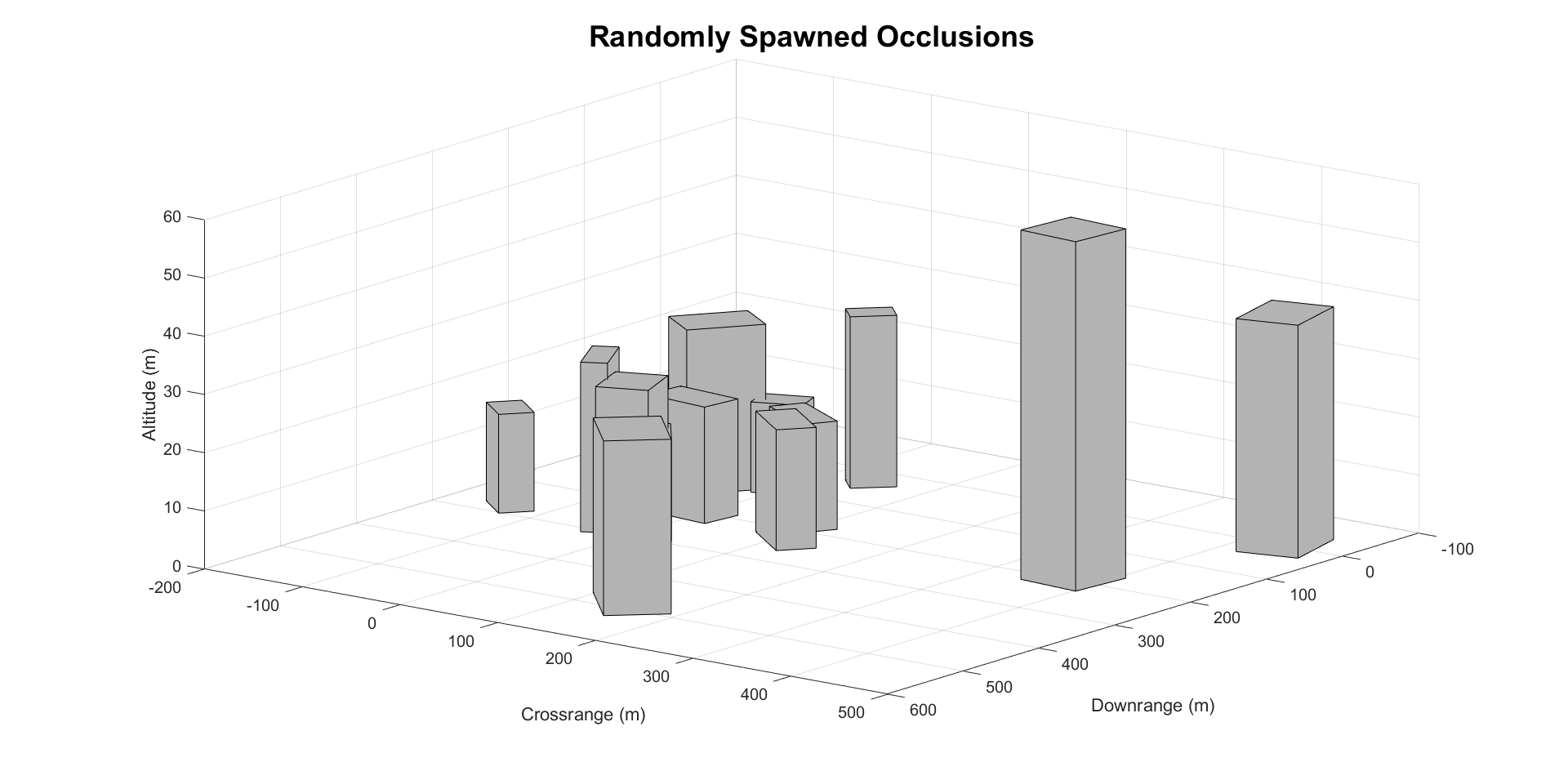
Occlusions:
In the simulation environment, the occlusions are represented as rectangular prisms with heights ranging from 20 to 60 meters. The widths and lengths range from 30 to 80 meters. The dimensions are randomly selected in each new episode, and the occlusions spawn at locations that are randomly placed within a prespecified bounding box. Thus the agent encounters a new environment in each episode, meaning the agent is not simply mapping the environment. The agent does not have access to any sort of map or the knowledge that this environment contains occlusions. At each simulation time step, a check is performed to see if the target is occluded. If this is the case, the agent will receive a large negative reward. Note that the agent is aware of the target’s location in the image frame even if it is occluded. Future work will relax this constraint.
Target Motions:
Three distinct target motions were used for training and evaluating the reinforcement learning agent. All the ground targets are modeled as point masses with planar motion. The base speed for all ground targets is randomly selected to be between 1 and 2 meters per second. Except for the evasive target, the target’s speed only changes when a new episode begins. Each type of target can randomly stop for a random amount of time between 30 and 60 seconds. At the beginning of each episode, the target’s initial heading is randomly selected to be between -80 and 80 degrees from the north.
- Randomly Moving Target: This ground target changes its heading by a random amount between -20 and 20 degrees from its current heading every 1.5 seconds.
- Sinusoidally Moving Target: This ground target traces out a sinusoid with an amplitude of 5 meters and a period of 25 meters. The amplitude increases linearly by 17.5 meters per period.
- Randomly Moving Evasive Target: The evasively moving ground target behaves the same as the randomly moving target, but the evasive target also speeds up when it can hear or see the agent. If the agent is visible by the target (i.e. the line of sight is not obstructed) and the agent is within 100 meters of the target, the target will begin to move 2-4 times faster than its base speed until the UAS exits this radius. The scaling factor for the speed is linearly dependent upon the agent's range to the target. If the agent is within 75 meters from the target, the target will also begin this speed-up procedure regardless of occlusions. This is to account for the acoustic signature of the UAS.
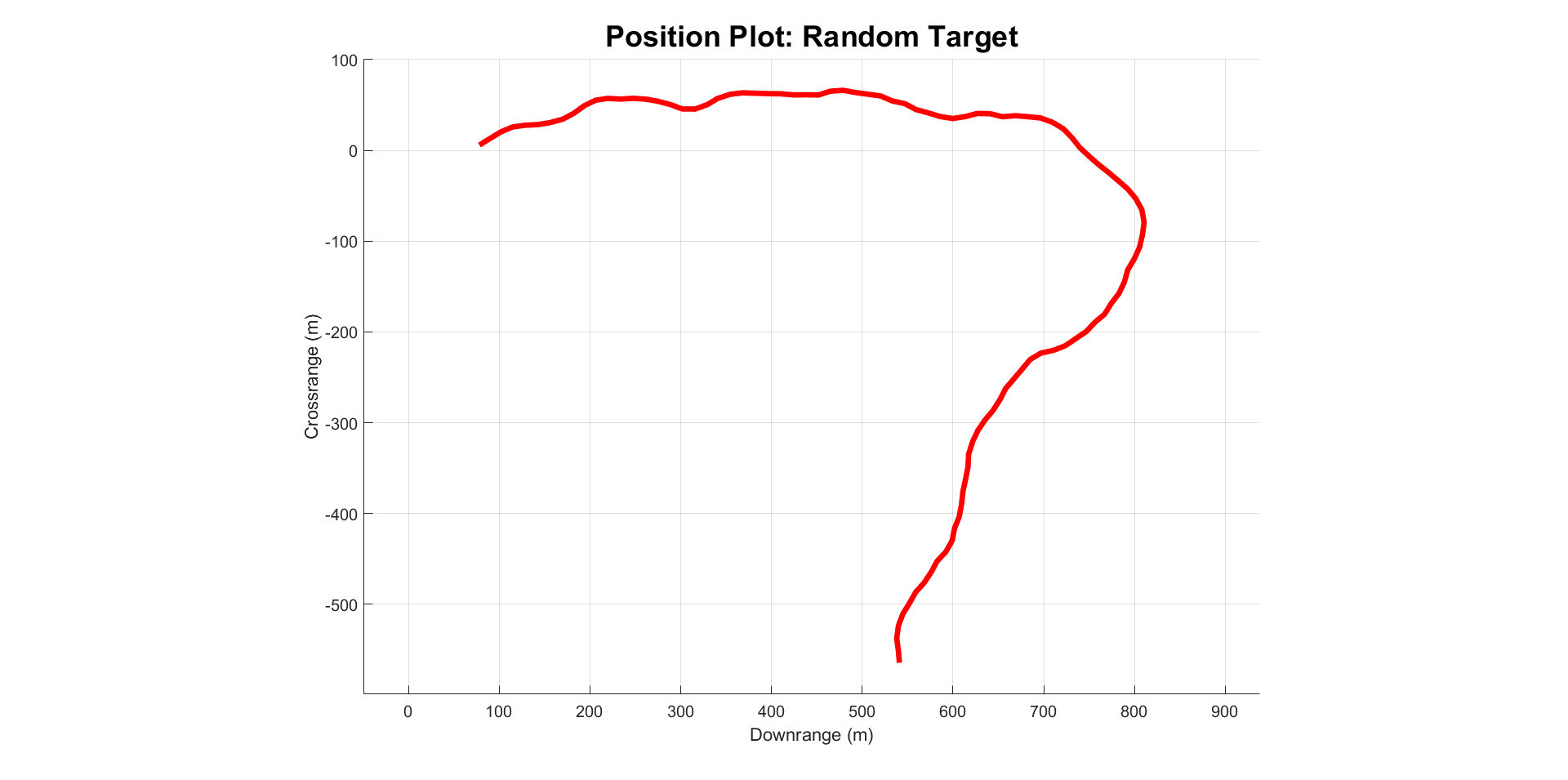
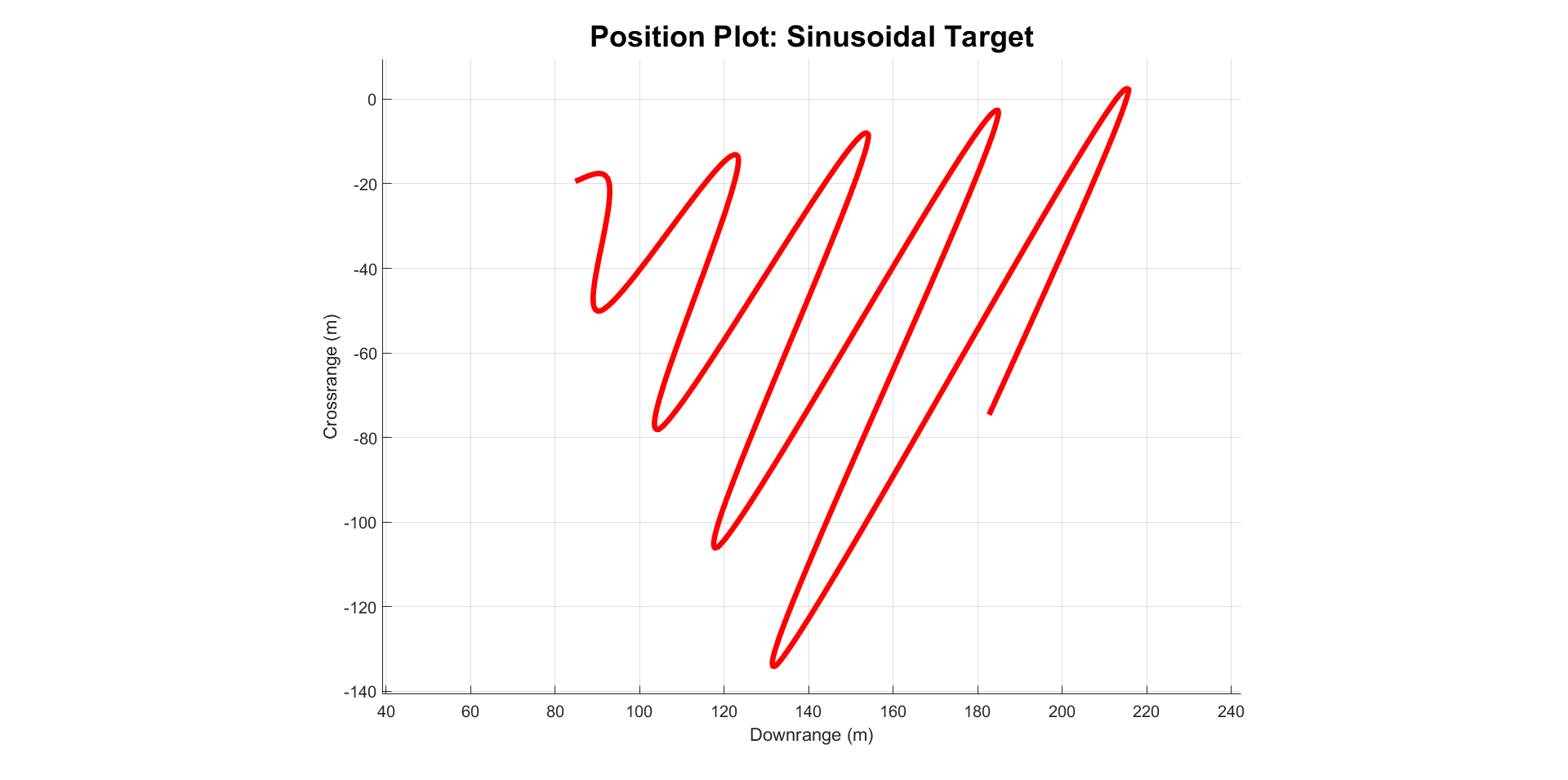
If the target encounters an occlusion, it traverses the edge of the occlusion until it can continue on its normal heading. This is done by projecting the target’s planned velocity onto the surface of the occlusion. Logical conditions inhibit the target from repeatedly changing direction. This stops the target from getting stuck in corners between occlusions. Notably, the occlusions can still block the line of sight between the target and the agent even though the target doesn’t enter the occlusions. This is because the occlusions have a vertical element and the agent moves in 3 dimensions. This creates a realistic simulation of the target going behind a building.
Animations
Below are select animations for the various possible environment and target combinations that were considered. While I only show two here, the rest of the animations can be found here.
Things to note about the animations:
- The agent is plotted in blue in the 3D plot, and the target is plotted in red. Additionally, the camera frame projection is plotted on the plane.
- The low-level controls, outputted by the NZSP controller are plotted as the actions.
- In the top right corner, the location of the target in the agent's image frame is plotted - ideal performance has the agent keeping the target near the center of the image frame.
- The animations are significantly sped up - the RL agent is able to conistently track the target for over 12 minutes.
Acknowledgment
This research was sponsored by CCDC-ARL and was accomplished under Cooperative Agreement Number W911NF-21-2-0064. The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of the ARL or the U.S. Government. The U.S. Government is authorized to reproduce and distribute reprints for Government purposes notwithstanding any copyright notation herein.
References
[1] Hill, A., Raffin, A., Ernestus, M., Gleave, A., Kanervisto, A., Traore, R., Dhariwal, P., Hesse, C., Klimov, O., Nichol, A., Plappert, M., Radford, A., Schulman, J., Sidor, S., and Wu, Y., “Stable Baselines,” https://github.com/hill-a/stable-baselines, 2018.
[2] Haarnoja, T., Zhou, A., Abbeel, P., and Levine, S., “Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor,” , 2018. https://doi.org/10.48550/ARXIV.1801.01290, URL https://arxiv.org/abs/1801.01290.